
Introduction
General-purpose LLMs are impressive until you ask them something specific. Ask a legal AI to interpret a contract clause using your firm's standard definitions, or a healthcare model to document a clinical encounter in your EHR's format, and the cracks appear fast. The model hedges, misuses terminology, or produces technically coherent but factually incorrect outputs. That gap is precisely what fine-tuning is designed to close.
Stanford HAI research found that general-purpose legal chatbots hallucinated in 58% to 82% of legal queries — a failure rate no enterprise can accept in production.
This guide is for founders, SMB leaders, and enterprise decision-makers evaluating whether to fine-tune an LLM on proprietary data. We'll cover what fine-tuning actually is, how it works, which method fits your situation, what drives success, and — just as importantly — when it's the wrong tool entirely.
Key Takeaways
- Fine-tuning continues an LLM's training on your labeled, domain-specific data to improve performance on enterprise tasks
- It modifies model weights; RAG and prompt engineering only change how you query the model, leaving weights untouched
- Three main approaches exist: full fine-tuning, PEFT/LoRA, and distillation, each suited to different compute budgets and use cases
- Data quality is the single largest determinant of success — volume matters far less
- Start with prompt engineering, then RAG — fine-tuning is only warranted when both fall short of your accuracy target
What Is LLM Fine-Tuning?
Fine-tuning takes a pre-trained large language model — one that already understands grammar, context, and general knowledge from billions of public documents — and continues its training on a smaller, task-specific dataset you control.
The model already knows how language works. Fine-tuning teaches it your language: your terminology, your output formats, and the reasoning patterns specific to your domain.
How It Differs from Related Approaches
Understanding where fine-tuning fits requires separating it from three approaches that often get conflated — and the confusion regularly leads to bad architectural decisions:
- Prompt engineering — Shapes model behavior through instructions at query time. No weights change. Fast to implement, but limited by what the base model already knows.
- RAG (Retrieval-Augmented Generation) — Pulls relevant documents from an external knowledge base at query time and passes them as context. No retraining required. Best for keeping responses grounded in current or frequently updated information.
- Training from scratch — Builds an entirely new model on your data from zero. Requires massive datasets and compute infrastructure. Impractical for nearly every enterprise.
Fine-tuning sits between prompt engineering and training from scratch: it uses an existing capable model as the foundation and adapts it efficiently with far less data and compute.
Why Enterprises Fine-Tune LLMs on Their Own Data
The core problem is simple: every general-purpose LLM was trained on public internet data. It has never seen your internal product documentation, your compliance policies, your proprietary terminology, or your customers' history.
Without fine-tuning, models:
- Default to broad, generic responses that miss domain nuance
- Misuse or misunderstand specialized jargon
- Ignore enterprise-specific formatting standards
- Hallucinate plausible-sounding but incorrect answers that erode user trust
Industries Where This Matters Most
| Industry | Key Use Case | Core Problem Without Fine-Tuning |
|---|---|---|
| Healthcare | Clinical documentation, EHR input | Generic summaries miss clinical specificity |
| Legal | Contract analysis, regulatory review | High hallucination rates on legal reasoning |
| Finance | Regulatory reporting, compliance | Incorrect terminology in regulated outputs |
| Software Dev | Internal codebase assistance | No knowledge of proprietary APIs or architecture |

McKinsey's 2024 State of AI research found that high-performing generative AI organizations are more likely to customize off-the-shelf models with proprietary data than lower-performing counterparts. The performance gap is measurable — and it's not the only reason to fine-tune.
Data privacy is an equally strong driver. By fine-tuning an open-source model that runs entirely on-premise, enterprises keep sensitive data off third-party API endpoints. This matters in healthcare (HIPAA), financial services (SOX, GLBA), and any vertical handling personally identifiable information.
How LLM Fine-Tuning Works: Approaches and Workflow
The general workflow follows a consistent pattern across all three approaches:
- Prepare labeled data — Build prompt-response pairs representative of real enterprise queries
- Select a base model — Choose a pre-trained model sized to your compute budget and performance needs
- Choose a fine-tuning method — Full fine-tuning, PEFT/LoRA, or distillation
- Run training — Update model weights on your dataset
- Evaluate — Benchmark against domain-specific test sets before deployment
- Deploy — Serve the adapted model, monitor for drift, retrain as needed
Which method fits depends on your dataset size, GPU budget, and how far your domain diverges from the base model's training data — each approach below involves different trade-offs on all three.
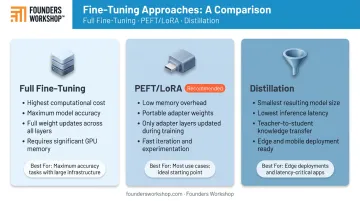
Full Fine-Tuning
Full fine-tuning updates every parameter in the model. It produces the highest degree of domain adaptation, but carries the steepest compute cost.
Hardware reality check: A 7B parameter model in FP32 requires roughly 28 GB of GPU RAM for weights alone, before accounting for gradients and optimizer states. Larger models multiply this proportionally.
Full fine-tuning is best suited when:
- Maximum accuracy is non-negotiable (regulated outputs, clinical documentation)
- The enterprise has dedicated ML infrastructure and large proprietary datasets
- The domain diverges significantly enough from the base model's training distribution
Parameter-Efficient Fine-Tuning (PEFT / LoRA)
PEFT freezes the base model's weights and trains only a small set of additional parameters. LoRA — the most widely used PEFT method — injects low-rank matrices into the model's transformer layers. The original LoRA paper reported up to a 10,000x reduction in trainable parameters versus full fine-tuning for GPT-3 175B, with competitive task performance.
Why PEFT is the recommended starting point for most enterprises:
- Far lower GPU memory requirements than full fine-tuning
- Guards against catastrophic forgetting (preserves the model's general capabilities)
- Produces small, portable adapter files that can be swapped without redeploying the base model
- Works well with limited data — meaningful improvements are achievable with a few hundred high-quality examples
- QLoRA (4-bit quantization + LoRA) can fine-tune a 65B parameter model on a single 48GB GPU
For most SMBs and mid-market enterprises without dedicated ML infrastructure, LoRA or QLoRA is the practical starting point.
Distillation
Distillation trains a smaller "student" model to replicate the behavior of a larger "teacher" model, using the teacher's outputs as training signal. The result is a leaner, faster model optimized for a specific task — contract extraction, support ticket routing, or document classification, for example.
Google Research demonstrated that a 770M-parameter T5 model outperformed a 540B-parameter PaLM model on certain benchmarks when trained via their distilling step-by-step method — more than 700x smaller.
This approach is well suited for:
- Customer-facing chatbots where latency is a hard constraint
- High-volume inference where per-query cost matters
- Edge deployments or environments with limited compute
Key Factors That Determine Fine-Tuning Success
Data Quality Comes First
This is where most fine-tuning projects fail — not in the training run, but in the data preparation that precedes it.
The LIMA paper (2023) demonstrated this clearly: a 65B LLaMA model fine-tuned on just 1,000 carefully curated prompt-response pairs produced strong alignment results. Volume wasn't the differentiator — curation was.
What good fine-tuning data looks like:
- Accurate and factually consistent throughout
- Representative of the actual queries the model will face in production
- Formatted consistently (prompt structure, response format, length)
- Free from internal contradictions and outdated information
- Balanced across the task types you need the model to handle
OpenAI's fine-tuning guidance explicitly recommends starting with 50 well-crafted demonstrations before scaling up — and scrutinizing each example for grammar, logic, and style consistency before adding it to the training set.
Data Volume, Format, and Preparation Time
Rough volume guidelines by method:
| Method | Minimum Viable Dataset | Recommended Range |
|---|---|---|
| PEFT/LoRA | 50–100 examples | 500–5,000 examples |
| Full Fine-Tuning | 5,000+ examples | Tens of thousands |
Data preparation — converting raw enterprise documents into structured prompt-response pairs — is consistently the most time-consuming phase of a fine-tuning project. A company with 10,000 internal knowledge base articles doesn't have 10,000 training examples. It has raw material. Each document must be chunked, labeled, and structured into usable pairs before training can begin.
Compute Requirements and Hyperparameters
Memory estimation rule: N billion parameters × 2 GB = approximate GPU memory needed for weights in FP16.
Training requires additional memory for gradients, optimizer states, and activation storage — typically 3–4x the inference footprint.
For enterprises without on-premise GPU infrastructure, cloud providers offer viable alternatives. AWS P5 instances (NVIDIA H100) and Google Cloud A2 instances (NVIDIA A100) handle production fine-tuning workloads, though pricing varies by region and availability.
Key hyperparameters to tune carefully:
- Learning rate — Too high causes instability; too low means the model doesn't adapt
- Batch size — Affects gradient quality and training stability
- Training epochs — Too few = underfitting; too many = memorization of training data
- LoRA rank and alpha — Control the capacity and scaling of adapter layers

The Cross-Functional Skills Gap
Production-grade fine-tuning requires data engineering (preparation and cleaning), ML engineering (training and evaluation), and deployment infrastructure — rarely found in a single person or small team.
Many startups and SMBs find it more practical to partner with an experienced AI development firm than to build this capability from scratch. Founders Workshop, for example, covers model training, vector database management, and custom GPT development — bringing the full cross-functional team that most growing companies can't staff internally.
When Fine-Tuning Isn't the Right Choice
Fine-tuning is a commitment. Before making it, rule out faster alternatives.
Skip fine-tuning if:
- Well-crafted prompts or few-shot examples already achieve acceptable output quality
- Your data changes frequently (live product catalogs, daily regulatory updates, real-time inventory) — a fine-tuned model will become stale without continuous retraining
- You don't have labeled prompt-response pairs and won't invest in creating them
- The task is information retrieval from a defined document corpus — RAG handles this better and more maintainably
Common misconceptions that lead to wasted fine-tuning efforts:
- "More data always produces better results" — A small, high-quality dataset consistently beats a large, noisy one
- "Fine-tuning will fix hallucinations" — It reduces them on in-distribution queries but doesn't eliminate them
- "Fine-tuning is the same as instruction following" — A well-prompted base model may already follow instructions adequately
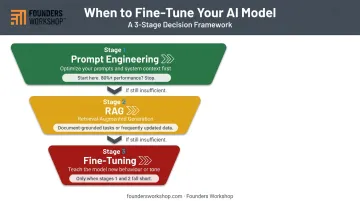
The Staged Decision Framework
Before committing to fine-tuning, work through this sequence:
- Prompt engineering first — Invest in well-structured system prompts and few-shot examples. If this achieves 80%+ of your target performance, stop here.
- RAG second — If the task requires grounding in specific documents or current information, implement retrieval before retraining anything.
- Fine-tuning last — Only proceed when neither prompt engineering nor RAG achieves the required accuracy or consistency for your use case. Validating each stage with real user feedback before moving to the next keeps technical risk low and ensures you're not over-engineering a solution that simpler methods could handle.
Frequently Asked Questions
What is the difference between fine-tuning an LLM and using RAG?
Fine-tuning modifies the model's weights using labeled training data — the learned knowledge becomes intrinsic to the model itself. RAG retrieves relevant documents at query time and passes them as context, without changing the model. The two approaches aren't mutually exclusive; RAFT (Retrieval Augmented Fine-Tuning) combines both for stronger domain-specific performance.
How much data do you need to fine-tune an LLM for enterprise use?
PEFT methods like LoRA can produce meaningful improvements with a few hundred to a few thousand high-quality labeled examples. Full fine-tuning typically requires tens of thousands. Quality and task relevance matter far more than raw volume — 200 well-structured examples outperform 2,000 inconsistent ones.
Is fine-tuning an LLM the same as training one from scratch?
No. Fine-tuning starts from a pre-trained model that already understands language and adapts it with a targeted dataset. Training from scratch requires massive datasets (hundreds of billions of tokens) and compute infrastructure that is impractical for all enterprises outside frontier AI labs.
How long does it take to fine-tune an LLM?
PEFT on a smaller dataset with a single modern GPU can complete in minutes to a few hours. Full fine-tuning of a large model on multi-GPU infrastructure can take days. Data preparation — not the training run itself — is usually what consumes the most calendar time.
What are the data privacy risks of fine-tuning on proprietary enterprise data?
Sensitive data used in training can become embedded in model weights and surface in outputs. Fine-tuning open-source models on-premise mitigates this compared to sending data to third-party API providers. NIST AI 600-1 flags training data privacy as a core generative AI risk, making compliance review non-negotiable in regulated industries.
How do I know if my enterprise data is ready for fine-tuning?
Your data is ready when it meets four criteria:
- Structured prompt-response pairs (not raw documents)
- Sufficient volume for your chosen method
- Clean, accurate content free from contradictions
- A clearly defined task the model is being trained to perform
If any of these are missing, data preparation — not model selection — should be your first investment.


